Industry analyst at Gartner. Global technology influencer, thought leader, strategist, author, trusted advisor and speaker. Thriving on #cloudcomputing, #cloudeconomics and #cloudmanagement. Based in Europe. Photographer. Guitarist. Singer. Beagle owner.
Gartner has just published the updated cloud IaaS scores for Amazon Web Services (AWS), Microsoft Azure and Google Cloud Platform (GCP). Gartner clients are normally used to see these updates coming once a year, but this time we decided to publish a quick incremental update, which is still based on last year’s 236-point Evaluation Criteria for Cloud Infrastructure as a Service (research by Elias Khnaser, @ekhnaser). Considering the pace at which the three hyperscale cloud providers are moving, we felt the need to reassess their coverage with higher frequency.
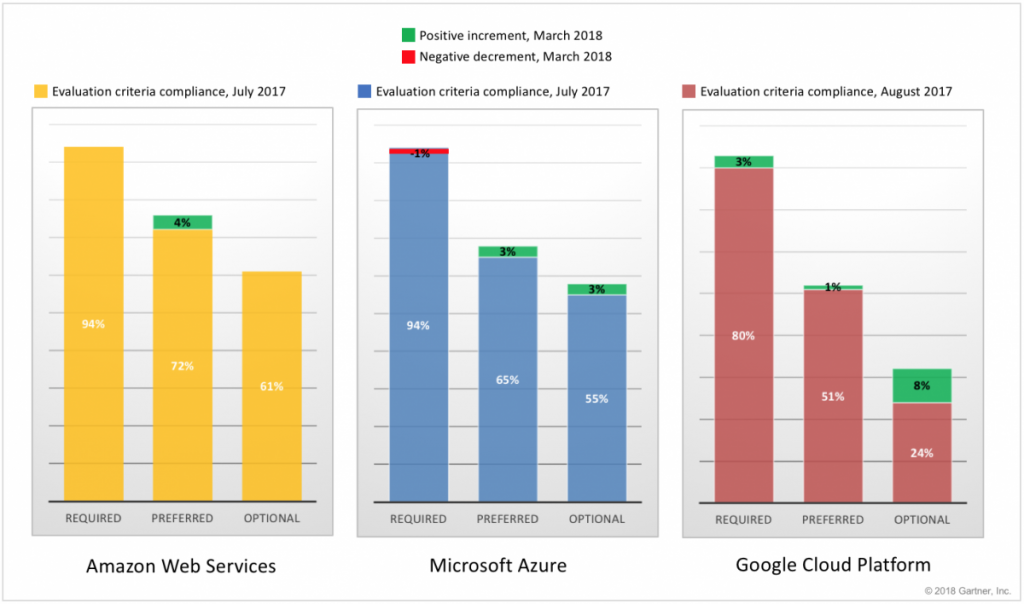
Compared to the previous assessments occurred mid-summer 2017, these new assessments show a steady growth in feature coverage by all three providers, with GCP leading the growth with an overall increment of 12 percent points. Azure follows with five additional percent points and AWS, which was the provider with the highest coverage also last year, marked an increment of four percent points. The figure below shows the details of the movements occurred within this update, broken down by required, preferred and optional criteria. It is interesting to note how some scores also went down (see Azure, required). When scores go down, it is not always due to providers removing features, but sometimes – like in this case – due to the modification of the applicability of the criteria’s scope.
What’s exactly behind these changes? Gartner for Technical Professionals (GTP) clients can access the three research notes to find out. With this update to the in-depth assessments, we have also introduced a “What’s New” summary section and a detailed “Change Log”, so that clients can quickly determine what are the provider’s updates that drove the changes in the scores.
What are the areas where providers are investing more? What are the gaps that still exist in some of their offerings? Are those gaps important or negligible for your organization? Find the answer to these and other questions by accessing the detailed research notes at:
In the meantime, Gartner is also redefining the full list of evaluation criteria for cloud IaaS in light of provider innovation and the shift in customer requirements as they adopt more public cloud services. The next update of the providers scores will most likely be based on the revised evaluation criteria. Stay tuned for new and potentially surprising results!
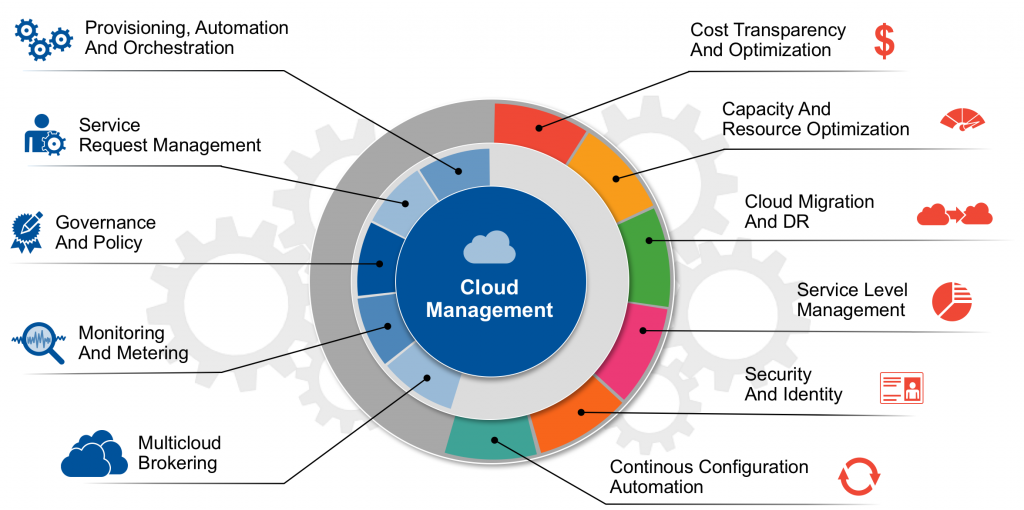
At Gartner, we’re often asked how to select cloud management platforms (CMP). We’ve been asked that question in the past, when a CMP was the software to transform virtualized data centers into API endpoints. We’re being asked the same question today, when a CMP is used to manage public clouds.
At Gartner Catalyst 2017 – one of the largest gathering of technical professionals – in one of my presentations I remarked how confused the market is. Even vendors don’t know whether they should call their product a CMP or not. In the last few years, the cloud management market has rapidly evolved. Public cloud providers have constantly released more native management tools. Organizations have continued to adopt public cloud services and have gradually abandoned the idea of building a cloud themselves. Public cloud services require the adoption of new processes and new tooling, such as in the areas of self-service enablement, governance and cost management. Finally, public cloud has to co-exist and co-operate with on-premises data centers in hybrid scenarios.
At Gartner, we’re committed to help our client organizations define their processes, translate them into management requirements and map them to market-leading tools. With the public cloud market maturing and playing a key role in the future of IT, we are now seeing the opportunity to make clarity and defining the functions that a CMP must provide.
My colleague Alan Waite and I are drafting the Evaluation Criteria (EC) for Cloud Management Platforms. An EC is a Gartner for Technical Professionals (GTP) branded research that lists the technical criteria of a specific technology and classifies them as required, preferred and optional. Clients can take an EC and use it to assess a vendor’s technical functionality. They can use it to form the basis for an RFP or even to simply define their management requirements. With our upcoming EC for CMPs, client organizations will be able to shed light on the confused cloud management market. They will be able to understand which tools to use for which management tasks and how to compare them against one another.
I’m bullish about the outcome of this research as I’m so looking forward to its publication. I’m extremely thankful to all the extended analyst community at Gartner who’s collaborating with me and Alan to increase the quality of this important piece of research. If you’re an existing Gartner client, don’t forget to track the “Cloud Computing” key initiative to be notified about the publication. if you’re willing to contribute to this research, feel free to schedule an inquiry or a vendor briefing with myself or Alan. Looking forward to the next update. Stay tuned!
In the last few days, the press has been dominated by countless interpretations of the myriad of AWS re:Invent announcements. Every article I read was trying (hard) to extract some kind of trend or direction from the overall conference. However, it was simply succeeding in providing a single and narrow perspective. AWS have simply tried to position itself as the “everything IT” (as my colleague Lydia Leong said in a tweet). With so many announcements (61, according to AWS), across so many area and in such a short time, it is extremely difficult for anyone to understand their impact without a more thorough analysis.
However, I won’t refrain from giving you also my own perspective, noting down a couple of things that stood out for me.
Serverless took the driver’s seat across the conference, no doubt. But servers did not move back into the trunk as you’d have expected. Lambda got a number of incremental updates. New services went serverless, such as Fargate (containers without the need to manage the orchestrator cluster) and the Aurora database. Finally, Amazon is headed to deliver platform as a service as it should’ve been from day one. A fully multi-tenant abstraction layer that handles your code, and that you pay only when your code is running.
However, we also heard about Nitro, a new lightweight hypervisor that can deliver near-metal performance. Amazon also announced bare-metal instances. These two innovations have been developed to attract more of the humongous number of workloads out there, which still require traditional servers to run. When the future seems to be going serverless, server innovation is still relevant. Why? Because by lowering the hypervisor’s overhead, Nitro can lead to better node density, better utilization and ultimately cost benefits for end users.
With regard to my main area of research, I was not impressed that only a couple of announcements were related to cloud management. Amazon announced an incremental update to CloudTrail (related to Lambda again, by the way) and the expansion of Systems Manager to support more AWS services. Systems Manager is absolutely one step towards what should be a more integrated cloud management experience. However (disclaimer: I’ve not seen it in action yet), my first impression is that it still focuses only on gaining (some) visibility and on automating (some) operational tasks. It’s yet another tool that needs integration with many others.
My cloud management conversations with clients tell me that organizations are struggling to manage and operate their workloads in the public cloud, especially when these live in conjunction with their existing processes and environments. Amazon needs to do more in this space to feel less like just-another-technology-silo and deliver a more unified management experience.
When both Andy Jassy or Werner Vogels were asked about multicloud, they both denied it. They said that most organizations stick with one primary provider for the great majority of their workloads. The reason? Because organizations don’t accept working at the least common denominator (LCD) between providers. Nor they want to become fluent in multiple APIs.
The reality is that multicloud doesn’t necessarily mean having to accept the LCD. Multicloud doesn’t imply having a cloud management platform (CMP) for each and every management task. It doesn’t imply having to make each and every workload portable. The LCD between providers would be indeed too much of a constraint for anyone adopting public cloud services.
On the contrary, we see that many organizations are willing to learn how to operate multiple providers. They want to do that to be able to place their workloads where it makes most sense, but also as a risk mitigation technique. In case they will ever be forced to exit one providers, they want to be ready to transfer their workloads to another one (obviously, with a certain degree of effort). Nobody wants to be constrained to work at the LCD level, but this is not a good excuse to stay single-cloud.
Amazon continues to innovate at an incredible pace, which seems to accelerate every year. AWS re:Invent 2017 was no exception. Now, organizations have more cloud services to support their business. But they also have many more choices to make. Picking the right combination of cloud services and tools is becoming a real challenge for organizations. Will Amazon do something about it? Or shall we expect hundreds of more service announcements at re:Invent 2018?
Today, I am proud to announce that I just published new research (available here) on how to manage public IaaS and PaaS cloud costs on AWS and Microsoft Azure. The research illustrates a multicloud governance framework that organizations can use to successfully plan, track and optimize cloud spending on an ongoing basis. The note also provides a comprehensive list of cloud providers’ native tools that can be leveraged to implement each step of the framework.
In the last 12 months of client inquiries, I felt a remarkable enthusiasm for public cloud services. Every organization I talked to was at some stage of public cloud adoption. Almost nobody was asking me “if” they should adopt cloud services but only “how” and “how fast”. However, these conversations also showed that only few organizations had realized the cost implications of public cloud.
In the data center, organizations were often over-architecting their deployments in order to maximize the return-on-investment of their hardware platforms. These platforms were refreshed every three-to-five years and sized to serve the maximum expected workload demand over that time frame. The cloud reverses this paradigm and demands that organizations size their deployment much more precisely or they’ll quickly run into overspending.
Futhermore, cloud providers price lists, pricing models, discounts and billing mechanisms can be complex to manage even for mature cloud users. Understanding the most cost-effective option to run certain workloads is a management challenge that organizations are often unprepared to address.
Using this framework will help you take control of your public cloud costs. It will make your organization achieve operational excellence in cost management and realize many of the promised cost benefits of public cloud.
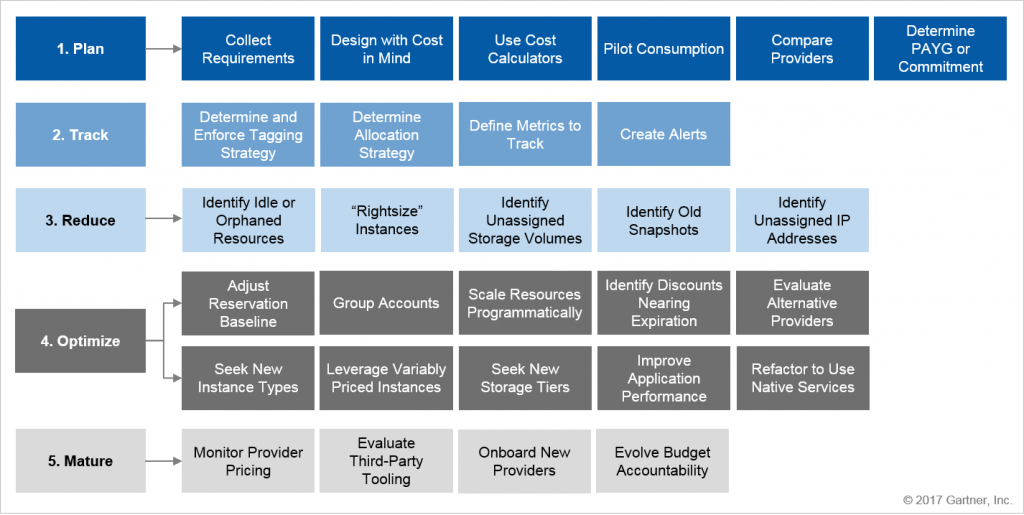
The Gartner’s framework for cost management comprises five main steps:
Plan: Create a forecast to set spending expectations.
Track: Observe your actual cloud spending and compare it with your budget to detect anomalies before they become a surprise.
Reduce: Quickly eliminate resources that waste cloud spending.
Optimize: Leverage the provider’s discount models and optimize your workload for cost.
Mature: Improve and expand your cost management processes on a continual basis.
If you recognize yourself in the above challenges, this new research note is an absolute recommended read. For a comprehensive description of the framework and the correspondent mapping of AWS and Microsoft Azure cost management tools, see “How To Manage Public Cloud Costs on AWS and Microsoft Azure”.
Last week in London, the distributed systems community got together at KubeCon EU to talk containers orchestration and Kubernetes. I was there too and I would like to share with you some insights from this exciting new world.
(Sorry for recycling the picture but I simply really liked it! – Credits go to Jessica Maslyn who created it).
Insights from Kubernetes
KubeCon is the official community conference of Kubernetes, despite it was not directly organised by Google, which instead is the by far top contributor of the open source project. Google also sent a few top-notch speakers, whose presence was already a good reason to pay a visit. Kelsey Hightower (@kelseyhightower) first and foremost, with his charm and authentic enthusiasm, was one of the most brilliant speakers, capable of winning the sympathy of everyone and earning respect at his first spoken sentence.
The probably most important announcement made around the Kubernetes project was its inclusion in the CNCF (Cloud Native Computing Foundation) for its governance going forward. This was generally welcomed as a positive initiative, as it has transferred control of the project to a wider committee, but still when the project was mature enough to keep its direction and mission.
Kubernetes is moving at an incredibly fast pace
Some hidden features were revealed during the talks, that even the most advanced users did not know about, and the announced roadmap was simply impressive. We heard users saying “we’re happy to see that any new feature we’ve been thinking of, is already somehow being considered”. This gives an idea of how much innovation is happening there and how much vendors and individual contributors are betting on Kubernetes to become a pervasive thing in the near future.
Its eco-system is doing amazing things
When an open source project just gets it right, it immediately develops an eco-system that understands its value and potential and it’s eager to contribute to it, by adding value on top. This is true for Kubernetes as well, and the exhibit area of the conference brought there the most talented individuals in the industry. I’ve been personally impressed by products like Rancher, that has got really far in very short time (thing that demonstrate clear vision and strong leadership) as well as things like Datadog and Weave Scope, that have shown strong innovation in data visualization, which they definitely brought to the next level.
Has it started to eat its eco-system’s lunch?
This is unavoidable when projects are moving so fast. The border between the project’s core features and what other companies develop as add-ons is fuzzy. And it’s always changing. What some organizations see as an opportunity at first, may become pointless at the next release of Kubernetes. But in the end, this is a community driven project and it’s the community that decides what should fit within Kubernets and what should be left to someone else. That’s why it’s so important to be involved in the community on a day-to-day basis, to know what’s being built and discussed. When I asked Shannon Williams, co-founder of Rancher Labs, how does he cope with this problem, he said you have to move faster, when part of your code is no longer required, just deprecate it and move on. Sure thing, you need to know how to move *that* fast, though!
Insights from reality
As product guy, I get excited about technology but I need to feel the real need of it, in a replicable manner. That’s why my ears were all for customers, end users and use cases.
The New York Times
Luckily, we heard a few use cases at the conference, the most notable of which was the New York Times using Kubernetes in production. Eric Lewis (@ericandrewlewis) took us through their journey from how they were giving developers a server, to enabling developers provision applications using Chef, to containers with Fleet and then Kubernetes. While Kubernetes looks like an end point, and we all know something else is coming next, but according to them, that’s definitely the best thing to deliver developers’ infrastructure at present.
Not (yet) a fit for everything
What stood out the most from real use cases, is how stateful workload is not that seamless to manage using containers and Kubernetes. It was demonstrated that it is possible, but still a pain to setup and maintain. The main reason is that state requires identity, you simply can’t flash out a database node (mapped to a pod) and start a brand new one, but you need to replace it with an exact copy of the one who’s gone. Every application needs to handle state, therefore every application needs to go through this. Luckily, it was said how the Kubernetes community is already working on PetSet that should exactly address this problem. Wait and see!
But the reality today is that Kubernetes is capable of handling only parts of an application. In fact one end customer told me that a great orchestration software should be able to handle both containerised and non-containerised workload. Thumbs up to him to remind us that the rest of the world of IT still exists!
Fast pace leads to caution
“The great things about standards is that there are so many to choose from” – #sotrue about this industry #KubeCon
This could be a real problem when you have a nascent eco-system that’s proposing equivalent but slightly different approaches to things. Which one to pick? Which horse to bet on? What if my chosen standard will be the one getting deprecated? And whilst competition is good even when it comes to open innovation, this also drives a totally understandable caution from end customers. I kind of miss the time when the standard was coming first and products were based upon them, but now we tend to welcome de facto standards instead, which take some time to prove their superiority.
In the end, what really matters is having more people using Kubernetes. More use cases will drive more innovation and will bring that stabilisation required to convince even the most cautious ones. When people on the conference stage were asked to give some advices on Kubernetes adoption, this is what they said:
Make sure you have someone who supports you business wise. Don’t leave it just a technology-driven decision but make sure the reasons and the opportunities it unlocks are well understood from the business owners of your organisation.
Stick at it. You’ll encounter some difficulties at the beginning but don’t give in. Stick at it and you’ll be rewarded.
Focus on moving to containers. That’s the hard thing in this revolution. Once you do that, adopting Kubernetes will be just a no brainer.
Right, move to containers. We heard this for a while. And containers are one of those not yet standardized things, despite the Open Container Initiative was kicked off a while ago. Docker is trying to become the de facto standard here but this seems to be business strategy driven rather than a contribution to the open source community. In fact, where were the Docker representatives at KubeCon? I have seen none of them.
Disclaimer: I have no personal involvement with KubeAcademy, the organizers of KubeCon, or with any of the mentioned companies and products. My employer is Flexiant and Flexiant was not an official sponsor of KubeCon. Flexiant is currently building a Kubernetes-based version of Flexiant Concerto.
It’s finally time to turn the page. We’re now right into the era of applications. They now are dictating how the rest of the world of IT should behave. Infrastructure has no longer the spotlight but it’s taking the passenger’s seat and merely delivering what it’s being asked for. What I sort of predicted almost 3 years ago in “Why the developer cloud will be the only one” is now happening.
That’s no good news for someone in this industry, I know. It’s much easier to talk (and sell) dumb CPU, RAM, storage space than it is about continuous integration, delivery, runtimes, inherently resilient services or even things like the CAP theorem. Sorry guys, if you want to remain in this industry, it’s time to step up and start understanding more about what’s happening up there, at the application level. Luckily, we have things that help us do so. Things like thenewstack.io (cheers @alexwilliams and team) who’s doing an awesome job introducing and explaining all these new concepts to the wider audience (including me!).
And to learn more about this phenomenon is also why I am going to attend KubeCon in London next week. For those who don’t know, KubeCon is the conference of Kubernetes, a Google-stewarded project for containers orchestration and scheduling. Some people will say it’s just one out of many right now but for us, at Flexiant, it’s just *the* one, as it possess the right level of abstraction to deliver container-based distributed applications. I’m going there to listen to industry leaders, innovators and just anyone who’s fully understood the new needs and who’s working every day to solve these new problems in new ways.
If you still don’t know what I’m talking about, read on. I’m going to take a step back and tell you a bit more about the drivers that caused applications to take over and why we needed different architectures, such as microservices, to be able to efficiently deliver and maintain that software that’s eating the world. If you’re short of time, you can simply watch the embedded video at the top of the page which should tell roughly the same story.
TL;DR
Software is now pervasive in people’s everyday’s life and it’s handling many of the new business transactions. Application architectures had to evolve in order to be able to cope with the increase in demand. Microservices is the optimal software architecture that combined with cloud infrastructure and containers can successfully fulfil new application requirements.
However, its numerous advantages are counter balanced by an increased complexity, which requires new orchestration tools that are able to join the dots and hold a global vision of how things are going. To achieve this, orchestration needs to happen at a higher level of the stack than what we had been previously seeing in the previous infrastructure era.
The rise of microservices
We can comfortably acknowledge how the way we do business has changed, how we see more and more transaction happening just online and how software is the only mean to achieve them. Software that, by the global nature of the relationships, needs to cope with a large number of users. It also needs to constantly deliver performance, to satisfy its user base as well as new features to keep up with competition, serve new needs and unlock new opportunities. You can easily understand how the traditional way of developing applications could just not power this kind of software. Monolithic applications were just too hard to scale, slow to update and difficult to maintain; on the other hand, the recently hyped PaaS was just too abstracted (compromising on developers’ freedom) and expensive to deliver the required efficiency.
That’s when microservices came in as the new preferred architectural pattern. Of course they had been around for a while even before they were called so but, as Bryan Cantrill (@bcantrill) said “[…] only now that we gave a name to it, it has been able to spread much beyond that initial use case”. That means that whenever we manage to label something in IT, this helps with diffusion, adoption and it serves as a baseline for further innovation. This has happened with cloud computing, and we see this happening again. For once, thank you marketing!
What exactly are microservices? We call microservices a software architecture that breaks down applications into many atomic interdependent components that talk to each other using language-agnostic APIs. A single piece of software gets broken into many smaller components, each of them publishing a API contract. Any other piece of that application can make use of that microservice just by addressing its API and without knowing anything about what’s behind it, including which language it’s written in, or which software libraries it uses. That unlocks a number of benefits, like single components that can be developed by different people, shared, taken from heterogeneous sources and reused a number of times. They can be updated independently, rolled back or grown in number whenever the application as whole needs to handle more workload. All of this without having to tear down the giant, heavy and slow monolith. Sounds great? Thumbs up.
Infrastructure for microservices
Setting up the infrastructure to host such distributed, complex and ever changing software architectures would be a real challenge, if we did not have cloud. In fact, infrastructure-as-a-service is a just no brainer to host microservices. Why? Because it provides commodity infrastructure, because you pay for what you use, because it’s just everywhere near your end users and because it never (well, almost) runs out of capacity. But what makes it so perfect for microservices is its programmability, required whenever a distributed application needs to deploy and re-deploy again and again, while adapting its footprint to its workload requirements at any given moment. We couldn’t have done it with traditional data centre software. Full stop.
When people think of IaaS, they think about virtual machines, virtual disks and network. Let’s call it traditional IaaS. And if you look at it, it’s not really fit for purpose for what we described above. In fact, virtual machines have zero visibility of what’s going on on top of their OS, let alone the interdependencies with other virtual machines hosting other services! So, we’ve seen things like configuration management systems (Chef, Puppet, Ansible, etc) taking over this part and, at the completion of the OS boot, to execute a number of configuration tasks to reach the full application deployment. It sort of worked so far, but at what price? First, virtual machines are slow. They need to be commissioned and then full OS needs to come up before it can execute anything. We’re talking about 20-30 seconds if it’s your lucky day up to several hours if it’s not. Second, virtual machines are heavy. The overhead that the hypervisor carries is just nonsense, as well as all that other multi-process and multi-user functionality that their OS was born to deliver, when in reality they simply need to host a little – micro – service. And configuration management systems? Even slower. Let alone their own weight (I’m looking for example at the full Ruby stack with Chef) they typically rely on external dependencies that, unfortunately, can change and generate different errors every time they are called in.
There was the need for something better. Oh wait, we already had something better! Containers. They existed for a while but they were having a seat in the previous infrastructure-centric IT world that was dominated by the expensive feature-full virtual machines. Guess what, containers understood (yeah, they apparently have a thinking brain!) that they could make the leap into the new application-centric world and shake hands to software developers. That’s how they recently become – rightly so – popular, as I wrote before in “The three reasons why Docker got it right”. Containers are just right to host microservices because (1) they’re micro as well, and they can start in a fraction of a second, (2) they’re further abstracted from the infrastructure and hence have no dependency on the infrastructure provider, (3) they are self-contained and don’t rely on external dependencies that can change but, most importantly, they are immutable. Any change within the container configuration can trigger the re-deployment of a new version of the container itself, which then can be rolled back if the result is not what we were expecting.
New challenges for new opportunities
As it happens every decade or so, the tech world solves big problems by tackling them from the side with disruptive solutions that unlock tremendous new opportunities. The veterans of this industry see these solutions and think “wow, that’s the right way of doing it!”, no question. However, new approaches typically also open up to a number of unprecedented challenges that could not even exist in legacy environments. These new challenges demand new solutions and that’s where the hottest (and most volatile) startup scene is currently playing a game.
Kubernetes, Docker, Mesos and all their eco-systems are right there, trying to overcome challenges that arise from the multitude of microservices that need to operate independently (providing a scalable and always available service) as well as with each other, cooperating to make up the whole application’s business logic. Networking challenges coming from microservices that need to communicate in a timely, predictable and secure way over the network. Monitoring challenges as you need to understand what’s going on when an end user presses a button, if any of the components is suffering from performance and needs to be scaled. And not to forget organisational challenges that come from when you potentially have so many teams working together on so many independent components that involve security, adaptability and access control, to name a few.
In the end, as we can’t stop software from eating more pieces of the world, we simply can try to improve its digestive system. Making software transparent to end users to generate positive emotions and ease transactions, while helping businesses not to miss any opportunity that’s out there are the ultimate goals. Making better software is a just a mean to get there and microservices, cloud and containers are headed in that direction. See you at Kubecon EU!
I thought I’d label 2015 as the year of the surrendering to the cloud. And by this I do not mean that mass adoption that every software vendor was waiting for, but surrendering to (1) the fact that cloud is now pervasive and it is no longer up for a debate and (2) to the dominance of Amazon Web Services.
A debate had been previously going way too long, on what are the real benefits of the cloud. And I’m not talking about end customers here, I’m talking about IT professionals, for whom new technologies should be bread and butter. But around cloud computing, they somehow showed the strongest skepticism, a high dose of arrogance (how many times I heard “we were doing cloud 20 years ago, but we were just not calling it that way”) and reluctancy to embrace change. The great majority of them underestimated the phenomenon to the point of challenging its usefulness or bringing it down to virtualisation in some other data center which is not here.
I asked myself why this has happened and I came to the conclusion that cloud has been just too disruptive, even for IT pros. To understand the benefits of the cloud in full, one had to make a mental leap. People naturally learn by small logical next steps, so cloud was interpreted just like the natural next step after having virtualised their data centres. But as I wrote more than three years ago in the blog post Cloud computing is not the evolution of virtualisation, the cloud came to solve a different problem and used virtualisation just as a delivery method to accomplish its goal. But finally, in 2015 I personally witnessed that long overdue increased level of maturity with respect to cloud technologies. Conversations I had with service providers and end customers’ IT pros were no longer about “if” to cloud or not to cloud, but about “what” and “when” instead.
What has helped achieving this maturity? I think it is the fact that nobody could ignore anymore the elephant in the room. The elephant called Amazon Web Services. That cloud pioneer and now well consolidated player that is probably five years ahead of its nearest competitor, in terms of innovation and feature richness. And not only they’re not ignoring it anymore, everyone wants to have a ride on it.
Many of those IT pros I mentioned are actually employed by major software vendors, maybe even leading their cloud strategy. Their initial misunderstanding of the real opportunity behind cloud adoption led to multi-million investments on the wrong products. And in 2015 (here we come to the surrendering number 2) we saw many of these failures surfacing up and demanding real change. Sometimes these changes were addressed with new acquisitions (like the EMC acquisition of Virtustream) or with the decision to co-opt instead of compete.
To pick some examples:
On Tuesday [Oct 6th] at AWS re:Invent, Rackspace launched Fanatical Support for AWS, beginning with U.S.-based customers. Non-U.S. customers will have to wait a while, although Rackspace will offer support for them in beta mode. In addition, Rackspace will also resell and offer support services for AWS’s elastic cloud as it’s now officially become an authorized AWS reseller.
Hewlett-Packard is dropping the public cloud that it offered as part of its Helion
“hybrid” cloud platform, ceding the territory to Amazon Web Services and Microsoft’s Azure. The company will focus on private cloud and traditional IT that its large corporate customers want, while supporting AWS and Azure for public cloud needs.
HP Enterprise’s latest strategy, which dovetails with earlier plans to focus on private and managed clouds, is to partner with Microsoft and become an Azure reseller.
What does this tell us? Most software vendors are now late to the game and are trying to enter the market by holding the hand of those who understood (and somewhat contribute to create) the public cloud market. But don’t we always say the cloud market is heading to commoditisation, why there seem to be no space for a considerable number of players? Certainly HP, VMware or IBM have the investment capacity of Amazon to grow big and compete head to head.
The reality is that we’re far from this commoditisation. If virtual machines may well be a commodity, they’re not more than a tiny bit of the whole cloud services offered for example by AWS (EC2 was mentioned only once during the two main keynotes at AWS re:Invent this year!). The software to enable the full portfolio of cloud services still make a whole lot of difference and to deliver it, this requires vision, leadership, understanding and a ton of talent. Millions of investments without the rest was definitely not the way.
Containers have been around for a while. But why did they finally get their well deserved popularity only with the rise of Docker? Was it just a matter of market maturity, or something else? Having worked at Joyent, I had the luck of being in the container business before Docker was even invented, and I would like to give you my take on that.
A brief history of containers
We hear this again and again in compute science: what we think has been recently invented by some computing visionary has actually its roots typically decades ago. It happened with hardware virtualisation (emulation), with the cloud client-server de-centralization (mainframes) and, yes, also with containers.
If you also started to hack with Unix back in the early 90’s you’ll certainly remember chroot. How many times I’ve used that to make sure my process wasn’t messing around with the main OS environment. And you’ll probably remember FreeBSD jails, that was adding all that required kernel-level isolation to implement the very first OS-level virtualisation system.
Sun Microsystem also believed strongly in containers and developed what they called “zones“, definitely the most powerful and well thought container system. But despite Sun believed in containers more than it did on hardware level virtualisation, the market moved towards the latter, not because it was the right approach but simply because it allowed the guest OS to stay untouched. Unfortunately Sun never managed to see much of the results of zones as nobody knows what really happened to them after the acquisition from Oracle. Luckily another company, Joyent, picked up the legacy of OpenSolaris with its SmartOS derivative. SmartOS is now used as the foundation of the Joyent Cloud with an improved version of zones at the very core of it.
At the same time, yet another company, Parallels (now Odin), stewarded OpenVZ, a Linux open-source project for OS-level virtualisation. The commercial version of it was called Virtuozzo and Parallels sold it as their virtualisation system of choice.
Since late 2000’s, Joyent and Parallels have been pioneering the container revolution but nobody talked about them as much as it’s now being done for Docker. Let’s try to understand why.
Positioning of containers
The easy conclusion would be that the market wasn’t just ready yet. We all know how timing is important when releasing something new and I’m sure this also played a role with containers. However, in my view, that’s not the main reason.
Let’s look at how these two companies were selling their container technology. Joyent made it all around performance and transparency: if you’re using a container instead of a virtual machine (i.e. hardware level virtualised) you can get an order of magnitude of performance increase, as well as total transparency and visibility of the underlying hardware. That’s absolutely spot on and relevant. But apparently it wasn’t enough.
Parallels made it all around density. Parallels’ target market was hosting companies and VPS providers, those who’s selling a single server for something like four bucks a month. So, if you’re selling a container instead of a virtual machine, you’ll be able to squeeze twice or three times the amount of servers on the same physical host. Therefore you can keep your prices lower and attract more customers. Given that you’re not reserving resources to a specific container, higher density is a real advantage that can be achieved without affecting performance too much. Absolutely true but again, it did not resonate too loud.
The need to lower the overhead
In the last few years, we also witnessed the desperate need to lower the overhead. Distributed system caused server sprawl. Thousands of under utilised VMs running what we call micro services, each with a heavy baggage to carry: a multi-process, multi-user full OS, whose features are almost totally useless to them. Therefore the research in lowering the overhead: from ZeroVM (acquired by Rackspace) to Cloudius Systems, that tried to rewrite the Linux kernel, chopping off those features that weren’t really necessary to run single process instances.
And then came Docker
Docker started as delivery model for the infrastructure behind the dotCloud PaaS, it was using containers to deliver something else. It was using containers to deliver application environments with the required agility and flexibility to deploy, scale and orchestrate. When Docker spun off, it added also the ability to package those environment and ship them to a central repository. Bingo. It turned containers as a simple mean to do something else. It wasn’t the container per se, it was what containers unlocked: the ability to package, ship and run isolated application environments in a fraction of a second.
And it was running on Linux. The most popular OS of all times.
Why Docker got it right
All of this made me think that there are three main reasons behind the success of Docker.
1. It used containers to unlock a totally new use case
The use case that container unlocked according to Joyent, Parallels and Docker were all different: performance of a virtual server in the case of Joyent, density of virtual servers in the case of Parallels and application delivery with Docker. They all make a lot of sense but the first two were focused on delivering a virtual server, Docker moved on and used containers to deliver applications instead.
2. It did not try to compete against virtual machines
Joyent and Parallels tried to position containers against virtual machines. You could do something better with containers when using a container instead of a virtual machine. And that was a tough sale. Trying to address the same use case as what everybody already acknowledged as the job of a VM was hard. It was right but it would have required much longer time to establish itself.
Docker did not compete with VMs and, as demonstration of that, most people are actually running Docker inside VMs today… even if Bryan Cantrill (@bcantrill), CTO of Joyent, would have something to say about it! Docker runs either on the bare metal or in a VM, it does not matter much when what you want to achieve is to build, package and run lightweight application environments for distributed systems.
3. It did not try to reinvent Unix but used Unix for what it was built for
Docker didn’t try to rewrite the Linux kernel. However it fully achieved the objective to reduce overhead. Containers can be used to run a single process with no burden to carry an entire OS. At the same time, the underlying host can make best use of its multi-process capabilities to effectively manage hundreds of containers.
Don’t get my wrong. I absolutely believe about the superiority of containers when compared to virtual machines. I think both Joyent and Parallels did an amazing job spreading out their benefits like no other. However, I also recognise in Docker the unique ability to have made them shine much brighter than anyone has ever done before.
In conclusion, co-opting with the established worlds of virtual machines and Linux to exploit the largest reach, while adding fundamental value to them was the reason behind Docker’s success. At the same time, looking at containers from an orthogonal perspective, not as the goal but as a mean to achieve something different than delivering a virtual server, is what landed containers on the mouth of everyone.
We have debated the cloud opportunity. Sounds old? Maybe. However, surprisingly enough, the majority of IT infrastructure buyers haven’t adopted it yet. Skepticism, natural resistance to change, staff self-preservations and other excuses are amongst the primary reasons for that. If you think about it, this is actually pretty normal when a technology is so much disrupting the status quo.
The title of the webinar “Cloud Can’t Wait” may sound like a way to build the hype but, with regard to cloud, I think we all concur that, by now, the hype is way over. As I’m sure we agree that, indeed, the cloud can’t wait. Those who’ve fully embraced it have demonstrated to have significant advantages over those who haven’t, and these advantages are directly affecting their competitiveness and even their ability to stay in business.
The opportunity is for everyone
We talked about the cloud focusing on the infrastructure side of it. We have deliberately excluded SaaS consumption from the statistics and the debate, as that has a totally different adoption curve and, when put in the same basked, can easily mislead the conclusions. So rule number one, treat SaaS numbers separately.
Michael Coté presented an interesting categorisation of cloud infrastructure services, segmented as follows:
Infrastructure-as-a-Service (IaaS): compute, storage and network “raw” infrastructure.
Platform-as-a-Service (PaaS): supporting developers and middleware integration they require.
Infrastructure-Software-as-a-Service (ISaaS): the applications required to manage IT infrastructure, including backup, archiving, disaster recovery (DR), capacity planning and, more generically, IT management as a service.
Seeing ISaaS as third category was pretty interesting to me as we all knew it existed but we never managed to label it correctly. And as Michael stated later on, expertise in this specific category is what some service providers, mostly those coming from the managed services space, can actually offer as value add on top of raw infrastructure, in order to win business in this space.
So what is this cloud opportunity we are referring to? Again, Michael explained it this way:
“[With a 29% year over year growth rate] there is the opportunity to get involved early and [as a vendor] participating in gathering lots of that cash. Instead, cloud buyers such as developers or enterprises, are not interested in participating in this growth, but in the innovation that comes out of this cloud space, they want to use this innovation and efficiency to really differentiate themselves in their own business”
So the opportunity is there and it is a win-win for everyone.
Why people are buying cloud and who are they?
If you ask yourself why people are buying cloud and what they’re using it for, you maybe won’t find the answers easily. That’s where the work of 451 Research becomes really helpful. As Michael told us, from the conversations they have everyday, it came out that most organisations use the cloud because of “the agility that it brings, the speed you can deploy IT and [afterwards] that you can use IT as a differentiator. [Because cloud] speeds time to market”.
To that, I would add that cloud also speeds the ability to deliver changes which translates into adaptability, essential for any chance of success in our rapidly transforming economy.
Michael continued on this topic:
“Over the past roughly 5 to 10 years much of the focus of IT has been on cost savings, keeping the lights on as cheaply as possible, but things are changing and qualitatively we see this in conversations we have all the time, companies are more interested in using IT to actually do something rather than just saving money, and cloud is perfectly shaped for offering that”
Great. This seems to be now well understood. The days of explaining to organisation that there is more to the cloud than the simple shift from CAPEX to OPEX, are gone.
Who are buying cloud infrastructure services today? My first answer went to:
“Developers. This word returns a lot whenever we talk about cloud. They’ve been the reason of the success of AWS, for sure. That’s because they just ‘get it’, they understand the advantages of the cloud around how they can transform infrastructure into code. For them, spinning a server is just like writing any other line of code for doing anything else. They managed to take advantage of the cloud from the very early days and they contributed to make cloud what it is today under many aspects”
With regard to enterprises, I also added:
“enterprises are [currently] investing in private clouds because that’s the most natural evolution of their traditional IT departments, but eventually, as they get to provide cloud, it’s gonna be extremely easy to get them to consume cloud [services] from third parties. That’s because cloud is more of a mindset than just a technology”
How can you profit from the cloud opportunity?
So you’re a service provider and you want to participate in the cloud opportunity. How do you do that? Michael suggests to use the “best execution venue” approach. That starts, as Michael explains, with understanding the type of workload or applications that you want to address. Then ask yourself what skills, capabilities and what assets do you have that you can leverage to address a specific type of workload? This will tell you what value you can bring on top of raw infrastructure in order to compete and take advantage of this fast-growing multi-billion market.
My comment on this was:
“Eventually service providers should not consider themselves just part of one of these [IaaS, PaaS or ISaaS, Ed.] segments. Eventually I think the segmentation of this type will not there anymore, and there will be another segmentation based more on use cases, where the service provider will specialise on something and will pick a few services to make the perfect portfolio to match a specific use case in a target market”
Yes I’m a big fan of the use case approach. As I’m a big fan of trying to understand what the cloud is exactly being used for. Even if the press tries to push the cloud as heavily commoditised service, you should never stop asking yourself what your customers are doing with it, what applications they’re running and what else you can do to make their life easier.
In any case, either you decide to leverage your existing capabilities or you try to learn what your customers want to do with your cloud, we all agreed around the following statement: it’s still very early days. As Michael again explains, there are still lots of options to get involved, it’s a great time to get involved, and the doors are definitely not closed.
I’d say they’re absolutely wide open. And many have already crossed the doorway. How about you?
Developers. Developers. Developers. I guarantee this was the most spoken word at DockerCon Europe 2014, the hottest software conference that just took place in Amsterdam last week. I was so lucky to get a ticket (as it sold out in a couple of days!) and be part of this amazing event that, despite a few complaints heard regarding too much of a “marketing love fest”, offered a lot in understanding market directions, trends and opportunities for software vendors.
So what is Docker? A container technology? No. Well, yes, but there is more to Docker. Despite being known as container technology, Docker is mainly a tool for packaging, shipping and running applications. A piece of infrastructure is now a simple means to do something else and requires no infrastructure skills to consume it. With containers now mainstream, the industry has now completed a further step towards making developers the main driver of IT infrastructure demand.
But at DockerCon, Docker employees appointed the project as a “platform” with the goal of making it easy to build and run distributed applications. A platform made of different components that are “included, but removable”. In fact, during one of the keynote sessions, Solomon Hykes (@solomonstre), creator of the Docker project, announced three of these new components that are now available alongside the well-known Docker engine:
Docker Machine
Docker Swarm
Docker Compose
As the community demanded, these three components have not been incorporated in the same binary as the container engine. But with this launch, Docker is now officially stepping into orchestration, clustering and scheduling.
Apart from the keynote, many of the breakout sessions were run by Docker partners, showing lots of interesting projects and more building blocks for creative engineers. In other sessions, organizations like ING Bank, Société Générale and BBC, explained how they use Docker and its benefits, including how Docker helps build their continuous delivery pipeline. Besides adopting the required technology stack, continuous delivery was also described as a fundamental organizational change that companies need to go through eventually. To this point, my most popular tweet during the two days has been a simple quote from Henk Kolk, Chief Architect at ING Bank Netherlands (@henkkolk):
ING journey to agile: “no more business analysts, testers, project managers. Those roles are gone. Now we have just engineers” #dockercon
Here’s my paraphrased version of Kolk’s session – Break the silos, empower engineers, build small product development teams and ship decentralized micro services. Cultural and organizational change has been described as important as the revolution in software architecture or cloud adoption. There can’t be one without the other. So you’d better be ready, educated and embrace it.
Docker Machine
The project that caught most of our attention at Flexiant was Docker Machine. It enables Docker to create machines into different clouds directly from the command line. My colleague Javi (@jpgriffo), author of krane.io, has been looking at it since it was a proposal and during the announcement of Docker Machine, we managed to send the very first pull request for the inclusion of a driver for Flexiant Concerto into the project, ahead of VMware and GCE. If Flexiant Concerto driver will be merged over the next days, Docker users will be able to go from “Zero to Docker” (as it was pitched by its author Ben Firshman – @bfirsh) in any cloud, with a single consistent driver. Exciting! We’re absolutely proud of this and we believe we have much more to give to the Docker community, given our expertise in cloud orchestration. Be prepared for more pull requests to follow.
The Risk
Docker has been blowing minds since the first days of the famous video (21 months ago!). It makes so much sense that it’s been adopted with a speed we’ve never seen in any open source project before. Even those who do not understand it are trying to jump on the bandwagon just to leverage its brand and market traction. This doesn’t come without risks. With a large community, an eco-system with important stakes and a commercial entity behind (Docker, Inc.) there will be conflicts of interests, with “overstepping” onto the domain of those partners that helped make Docker what is today. We’ve already seen this with the CoreOS launch of Rocket a couple of days ago.
Docker, Inc. needs to drive revenue and, despite seeing Solomon Hykes make a lot of effort to keep an impartial and honest governance over his baby, I’m sure it’s not going to be a painless process. Good luck Solomon!
The Opportunity
High risks usually mean high potential return. The return here can be high, not just for Docker, Inc., but for the whole world of IT. Learning Docker and understanding its advantages can drive the development of applications in a totally different way. Not having to create a heavy resource-wasting virtual machine (VM) for everything will boost the rise of micro services, distributed applications and, by reflection, cloud adoption. With this, comes scalability, flexibility, adaptability, innovation and progress. I don’t know if Docker will still be such a protagonist over the next year or two, but what I know is that it will have fundamentally changed the way we build and deliver software.