Industry analyst at Gartner. Global technology influencer, thought leader, strategist, author, trusted advisor and speaker. Thriving on #cloudcomputing, #cloudeconomics and #cloudmanagement. Based in Europe. Photographer. Guitarist. Singer. Beagle owner.
I often discuss with clients in infrastructure and operations on whether their organizations should adopt Kubernetes to make their applications portable. If you also have this question, the answer is: no.
Actually, the full story: adopt Kubernetes for the many benefits it provides to application development and architecture and get portability as a side effect. But do not make portability your primary driver for adopting the technology. This thesis is well expanded in the document that Richard Watson, Alan Waite and I have crafted during lockdown this spring: “Assessing Kubernetes for Hybrid and Multicloud Application Portability” (paywall).
Kubernetes or not, application portability always comes at a price that you must be willing to pay – the “portability tax”. Gartner’s advice is to make this decision application by application, based on the likelihood that it will be moved in the future, and how fast that needs to happen. In fact, non-portable applications may still be moved, it will just require more time to execute the transformation.
What is the likelihood that applications change infrastructure provider through their lifespan?
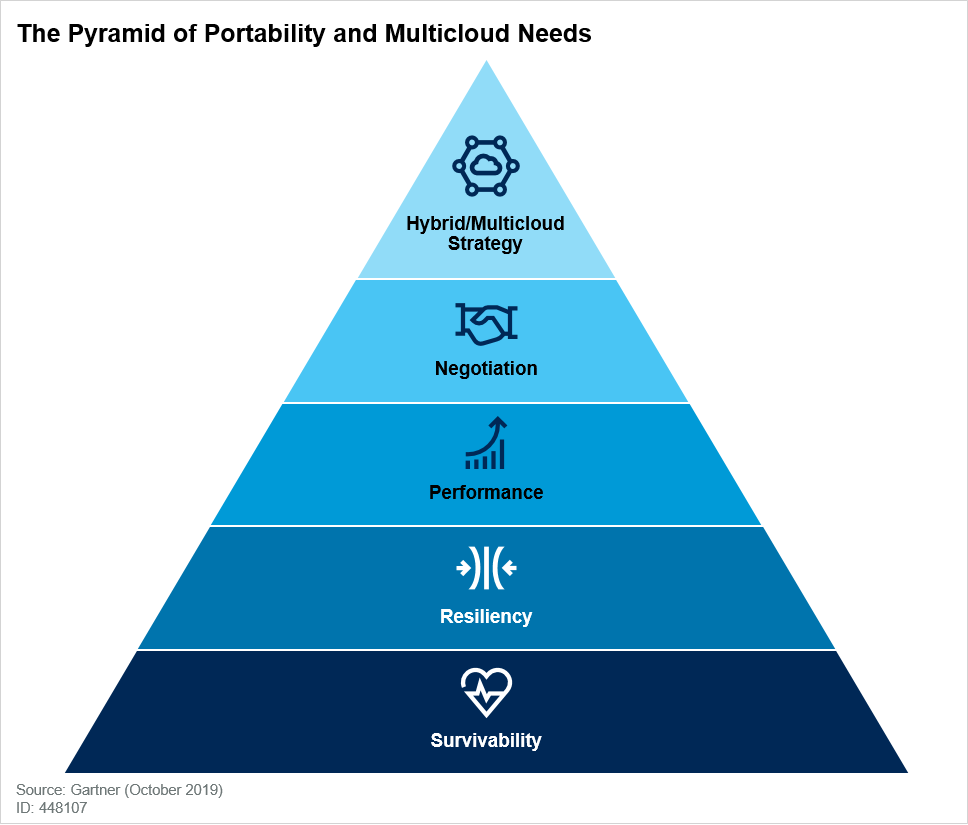
Inquiries show that this likelihood is actually very low. Once deployed in a provider, applications tend to stay there. This is due to data lakes being hard – and expensive – to port and, therefore, end up acting as centers of gravity. The figure below shows the Gartner pyramid of portability, which illustrates basic motivations (at the bottom) and more strategic ones (at the top) for designing portable applications.
For each of your application, ask yourself why portability is important to you. Is it to guarantee survivability? To increase your negotiation leverage with the cloud provider? To mitigate vendor lock-in? The higher you are in the pyramid, the least likely it is that you’ll have those needs.
Kubernetes facilitates portability because it helps standardize our software development life cycle and, most importantly, our operating model. However, it also adds management overhead to our organization, it forces us to engage with commercial vendors and to completely rearchitect our applications. Implementing portability with Kubernetes also requires avoiding any dependency that ties the application to the infrastructure provider, such as the use of cloud provider’s native services. Often, these services provide the capabilities that drove us to the cloud in the first place.
In conclusion, the portability tax is high. Make sure to pay it only for applications that truly need it and that are likely to switch infrastructure provider at some point. For all the others, don’t choose Kubernetes on the basis of a universal portability principle, just because it “sounds right”. On the contrary, adopt Kubernetes for agility, scalability and for modernizing your application architectures.
Last week in London, the distributed systems community got together at KubeCon EU to talk containers orchestration and Kubernetes. I was there too and I would like to share with you some insights from this exciting new world.
(Sorry for recycling the picture but I simply really liked it! – Credits go to Jessica Maslyn who created it).
Insights from Kubernetes
KubeCon is the official community conference of Kubernetes, despite it was not directly organised by Google, which instead is the by far top contributor of the open source project. Google also sent a few top-notch speakers, whose presence was already a good reason to pay a visit. Kelsey Hightower (@kelseyhightower) first and foremost, with his charm and authentic enthusiasm, was one of the most brilliant speakers, capable of winning the sympathy of everyone and earning respect at his first spoken sentence.
The probably most important announcement made around the Kubernetes project was its inclusion in the CNCF (Cloud Native Computing Foundation) for its governance going forward. This was generally welcomed as a positive initiative, as it has transferred control of the project to a wider committee, but still when the project was mature enough to keep its direction and mission.
Kubernetes is moving at an incredibly fast pace
Some hidden features were revealed during the talks, that even the most advanced users did not know about, and the announced roadmap was simply impressive. We heard users saying “we’re happy to see that any new feature we’ve been thinking of, is already somehow being considered”. This gives an idea of how much innovation is happening there and how much vendors and individual contributors are betting on Kubernetes to become a pervasive thing in the near future.
Its eco-system is doing amazing things
When an open source project just gets it right, it immediately develops an eco-system that understands its value and potential and it’s eager to contribute to it, by adding value on top. This is true for Kubernetes as well, and the exhibit area of the conference brought there the most talented individuals in the industry. I’ve been personally impressed by products like Rancher, that has got really far in very short time (thing that demonstrate clear vision and strong leadership) as well as things like Datadog and Weave Scope, that have shown strong innovation in data visualization, which they definitely brought to the next level.
Has it started to eat its eco-system’s lunch?
This is unavoidable when projects are moving so fast. The border between the project’s core features and what other companies develop as add-ons is fuzzy. And it’s always changing. What some organizations see as an opportunity at first, may become pointless at the next release of Kubernetes. But in the end, this is a community driven project and it’s the community that decides what should fit within Kubernets and what should be left to someone else. That’s why it’s so important to be involved in the community on a day-to-day basis, to know what’s being built and discussed. When I asked Shannon Williams, co-founder of Rancher Labs, how does he cope with this problem, he said you have to move faster, when part of your code is no longer required, just deprecate it and move on. Sure thing, you need to know how to move *that* fast, though!
Insights from reality
As product guy, I get excited about technology but I need to feel the real need of it, in a replicable manner. That’s why my ears were all for customers, end users and use cases.
The New York Times
Luckily, we heard a few use cases at the conference, the most notable of which was the New York Times using Kubernetes in production. Eric Lewis (@ericandrewlewis) took us through their journey from how they were giving developers a server, to enabling developers provision applications using Chef, to containers with Fleet and then Kubernetes. While Kubernetes looks like an end point, and we all know something else is coming next, but according to them, that’s definitely the best thing to deliver developers’ infrastructure at present.
Not (yet) a fit for everything
What stood out the most from real use cases, is how stateful workload is not that seamless to manage using containers and Kubernetes. It was demonstrated that it is possible, but still a pain to setup and maintain. The main reason is that state requires identity, you simply can’t flash out a database node (mapped to a pod) and start a brand new one, but you need to replace it with an exact copy of the one who’s gone. Every application needs to handle state, therefore every application needs to go through this. Luckily, it was said how the Kubernetes community is already working on PetSet that should exactly address this problem. Wait and see!
But the reality today is that Kubernetes is capable of handling only parts of an application. In fact one end customer told me that a great orchestration software should be able to handle both containerised and non-containerised workload. Thumbs up to him to remind us that the rest of the world of IT still exists!
Fast pace leads to caution
“The great things about standards is that there are so many to choose from” – #sotrue about this industry #KubeCon
This could be a real problem when you have a nascent eco-system that’s proposing equivalent but slightly different approaches to things. Which one to pick? Which horse to bet on? What if my chosen standard will be the one getting deprecated? And whilst competition is good even when it comes to open innovation, this also drives a totally understandable caution from end customers. I kind of miss the time when the standard was coming first and products were based upon them, but now we tend to welcome de facto standards instead, which take some time to prove their superiority.
In the end, what really matters is having more people using Kubernetes. More use cases will drive more innovation and will bring that stabilisation required to convince even the most cautious ones. When people on the conference stage were asked to give some advices on Kubernetes adoption, this is what they said:
Make sure you have someone who supports you business wise. Don’t leave it just a technology-driven decision but make sure the reasons and the opportunities it unlocks are well understood from the business owners of your organisation.
Stick at it. You’ll encounter some difficulties at the beginning but don’t give in. Stick at it and you’ll be rewarded.
Focus on moving to containers. That’s the hard thing in this revolution. Once you do that, adopting Kubernetes will be just a no brainer.
Right, move to containers. We heard this for a while. And containers are one of those not yet standardized things, despite the Open Container Initiative was kicked off a while ago. Docker is trying to become the de facto standard here but this seems to be business strategy driven rather than a contribution to the open source community. In fact, where were the Docker representatives at KubeCon? I have seen none of them.
Disclaimer: I have no personal involvement with KubeAcademy, the organizers of KubeCon, or with any of the mentioned companies and products. My employer is Flexiant and Flexiant was not an official sponsor of KubeCon. Flexiant is currently building a Kubernetes-based version of Flexiant Concerto.
It’s finally time to turn the page. We’re now right into the era of applications. They now are dictating how the rest of the world of IT should behave. Infrastructure has no longer the spotlight but it’s taking the passenger’s seat and merely delivering what it’s being asked for. What I sort of predicted almost 3 years ago in “Why the developer cloud will be the only one” is now happening.
That’s no good news for someone in this industry, I know. It’s much easier to talk (and sell) dumb CPU, RAM, storage space than it is about continuous integration, delivery, runtimes, inherently resilient services or even things like the CAP theorem. Sorry guys, if you want to remain in this industry, it’s time to step up and start understanding more about what’s happening up there, at the application level. Luckily, we have things that help us do so. Things like thenewstack.io (cheers @alexwilliams and team) who’s doing an awesome job introducing and explaining all these new concepts to the wider audience (including me!).
And to learn more about this phenomenon is also why I am going to attend KubeCon in London next week. For those who don’t know, KubeCon is the conference of Kubernetes, a Google-stewarded project for containers orchestration and scheduling. Some people will say it’s just one out of many right now but for us, at Flexiant, it’s just *the* one, as it possess the right level of abstraction to deliver container-based distributed applications. I’m going there to listen to industry leaders, innovators and just anyone who’s fully understood the new needs and who’s working every day to solve these new problems in new ways.
If you still don’t know what I’m talking about, read on. I’m going to take a step back and tell you a bit more about the drivers that caused applications to take over and why we needed different architectures, such as microservices, to be able to efficiently deliver and maintain that software that’s eating the world. If you’re short of time, you can simply watch the embedded video at the top of the page which should tell roughly the same story.
TL;DR
Software is now pervasive in people’s everyday’s life and it’s handling many of the new business transactions. Application architectures had to evolve in order to be able to cope with the increase in demand. Microservices is the optimal software architecture that combined with cloud infrastructure and containers can successfully fulfil new application requirements.
However, its numerous advantages are counter balanced by an increased complexity, which requires new orchestration tools that are able to join the dots and hold a global vision of how things are going. To achieve this, orchestration needs to happen at a higher level of the stack than what we had been previously seeing in the previous infrastructure era.
The rise of microservices
We can comfortably acknowledge how the way we do business has changed, how we see more and more transaction happening just online and how software is the only mean to achieve them. Software that, by the global nature of the relationships, needs to cope with a large number of users. It also needs to constantly deliver performance, to satisfy its user base as well as new features to keep up with competition, serve new needs and unlock new opportunities. You can easily understand how the traditional way of developing applications could just not power this kind of software. Monolithic applications were just too hard to scale, slow to update and difficult to maintain; on the other hand, the recently hyped PaaS was just too abstracted (compromising on developers’ freedom) and expensive to deliver the required efficiency.
That’s when microservices came in as the new preferred architectural pattern. Of course they had been around for a while even before they were called so but, as Bryan Cantrill (@bcantrill) said “[…] only now that we gave a name to it, it has been able to spread much beyond that initial use case”. That means that whenever we manage to label something in IT, this helps with diffusion, adoption and it serves as a baseline for further innovation. This has happened with cloud computing, and we see this happening again. For once, thank you marketing!
What exactly are microservices? We call microservices a software architecture that breaks down applications into many atomic interdependent components that talk to each other using language-agnostic APIs. A single piece of software gets broken into many smaller components, each of them publishing a API contract. Any other piece of that application can make use of that microservice just by addressing its API and without knowing anything about what’s behind it, including which language it’s written in, or which software libraries it uses. That unlocks a number of benefits, like single components that can be developed by different people, shared, taken from heterogeneous sources and reused a number of times. They can be updated independently, rolled back or grown in number whenever the application as whole needs to handle more workload. All of this without having to tear down the giant, heavy and slow monolith. Sounds great? Thumbs up.
Infrastructure for microservices
Setting up the infrastructure to host such distributed, complex and ever changing software architectures would be a real challenge, if we did not have cloud. In fact, infrastructure-as-a-service is a just no brainer to host microservices. Why? Because it provides commodity infrastructure, because you pay for what you use, because it’s just everywhere near your end users and because it never (well, almost) runs out of capacity. But what makes it so perfect for microservices is its programmability, required whenever a distributed application needs to deploy and re-deploy again and again, while adapting its footprint to its workload requirements at any given moment. We couldn’t have done it with traditional data centre software. Full stop.
When people think of IaaS, they think about virtual machines, virtual disks and network. Let’s call it traditional IaaS. And if you look at it, it’s not really fit for purpose for what we described above. In fact, virtual machines have zero visibility of what’s going on on top of their OS, let alone the interdependencies with other virtual machines hosting other services! So, we’ve seen things like configuration management systems (Chef, Puppet, Ansible, etc) taking over this part and, at the completion of the OS boot, to execute a number of configuration tasks to reach the full application deployment. It sort of worked so far, but at what price? First, virtual machines are slow. They need to be commissioned and then full OS needs to come up before it can execute anything. We’re talking about 20-30 seconds if it’s your lucky day up to several hours if it’s not. Second, virtual machines are heavy. The overhead that the hypervisor carries is just nonsense, as well as all that other multi-process and multi-user functionality that their OS was born to deliver, when in reality they simply need to host a little – micro – service. And configuration management systems? Even slower. Let alone their own weight (I’m looking for example at the full Ruby stack with Chef) they typically rely on external dependencies that, unfortunately, can change and generate different errors every time they are called in.
There was the need for something better. Oh wait, we already had something better! Containers. They existed for a while but they were having a seat in the previous infrastructure-centric IT world that was dominated by the expensive feature-full virtual machines. Guess what, containers understood (yeah, they apparently have a thinking brain!) that they could make the leap into the new application-centric world and shake hands to software developers. That’s how they recently become – rightly so – popular, as I wrote before in “The three reasons why Docker got it right”. Containers are just right to host microservices because (1) they’re micro as well, and they can start in a fraction of a second, (2) they’re further abstracted from the infrastructure and hence have no dependency on the infrastructure provider, (3) they are self-contained and don’t rely on external dependencies that can change but, most importantly, they are immutable. Any change within the container configuration can trigger the re-deployment of a new version of the container itself, which then can be rolled back if the result is not what we were expecting.
New challenges for new opportunities
As it happens every decade or so, the tech world solves big problems by tackling them from the side with disruptive solutions that unlock tremendous new opportunities. The veterans of this industry see these solutions and think “wow, that’s the right way of doing it!”, no question. However, new approaches typically also open up to a number of unprecedented challenges that could not even exist in legacy environments. These new challenges demand new solutions and that’s where the hottest (and most volatile) startup scene is currently playing a game.
Kubernetes, Docker, Mesos and all their eco-systems are right there, trying to overcome challenges that arise from the multitude of microservices that need to operate independently (providing a scalable and always available service) as well as with each other, cooperating to make up the whole application’s business logic. Networking challenges coming from microservices that need to communicate in a timely, predictable and secure way over the network. Monitoring challenges as you need to understand what’s going on when an end user presses a button, if any of the components is suffering from performance and needs to be scaled. And not to forget organisational challenges that come from when you potentially have so many teams working together on so many independent components that involve security, adaptability and access control, to name a few.
In the end, as we can’t stop software from eating more pieces of the world, we simply can try to improve its digestive system. Making software transparent to end users to generate positive emotions and ease transactions, while helping businesses not to miss any opportunity that’s out there are the ultimate goals. Making better software is a just a mean to get there and microservices, cloud and containers are headed in that direction. See you at Kubecon EU!